卷积神经网络cnn中最基本的操作是卷积和池化,而卷积操作又赋予了特征提取的功能,本文将从卷积操作的具体运算过程入手总结cnn的相关应用。我使用的数据集为mnist手写数字的dataset,每一个样本为28x28的数字灰度图像。卷积神经网络不仅在图像处理上应用广泛,现在在NLP领域也越来越多的使用cnn进行包括分类在内的各种应用。写这篇文章的目的主要是在学习的过程中同时对卷积cnn做一个梳理,如有不正之处敬请指出。本文涉及到的主要内容包括:
- 卷积及CNN
- VGG网络
- FCN与语义分割
- RCNN与目标检测
卷积
卷积操作在高等数学和概率论中均有介绍,但是当时学时并没有理解其本质的意义,关于卷积操作的具体解释可以参看知乎问题
卷积的含义本质其实是一个函数在另一个函数上的加权叠加,对于一个系统S来说,如果有一个操作f对其产生某种作用,这种作用每次的大小都不一样与时间有关记为f(t),而这种作用的强度又会随着时间的变化而不断减弱,记为\(g(\delta t)\)表示这种操作的强度与时间的关系,当f对S持续产生作用时,如果我们要计算时间为T时系统的强度,我们需要计算之前的每次f操作的累加,这样可以表示为\(f(t)*g(T-t)\)的加和,用来表示之前所有f乘上其对第T时刻的权重来表示最终的效果,T-t就是f的时刻与最终时刻的差值,g是与这个差值有关的,这样就解释了这里为什么是T-t,这个负号一直是卷积最难以解释的地方。
卷积与图像处理
对于图像的处理,卷积操作其实基本上可以当做像素矩阵的点乘操作,这里利用mnist训练集中的第一张图片来测试一下,3x3的卷积核对于图像的影响。
对于图像进行卷积运算可以参考如下资料,作者对于各种不同类型的卷积操作都进行了解释,包括是否进行padding,strides的大小,以及转置卷积和dilated卷积操作,解释得比较详细并配以相应的动画。注:dilated卷积在tensorflow中为可选操作。
- https://github.com/vdumoulin/conv_arithmetic
- A guide to convolution arithmetic for deep learning
关于实现的话,对于卷积操作我们需要确定的是卷积核kernel的大小ksize(这里取3)、步长stride,这里首先我们测试一下如下进行平均的卷积核对手写图片的影响,步长暂定取1。下面的out表示输出的像素矩阵,out_size的计算方式是固定的,如果要更严谨的话需要确保out_size的值刚好为整数。
weights = np.array([[1,1,1],
[1,1,1],
[1,1,1]]).astype('float32')
weights /= np.sum(weights)
out_size = (m-(ksize-1)) / stride
out = np.zeros((out_size,out_size))
现在卷积核有了,接下来就是如何进行计算了,利用numpy的点乘操作,将卷积核和要卷积的部分都reshape成向量,然后进行点乘。
weights_col = np.reshape(weights, [-1,1])
for i in range(0,out_size):
for j in range(0,out_size):
print(i,j),
source = test[i*stride:i*stride+ksize, j*stride:j*stride+ksize]
source_col = np.reshape(source, [-1,1])
out_pixel = int(np.dot(source_col.T, weights_col))
out[i,j] = out_pixel

如上为卷积的效果,最左边为原图数字5的图像,中间为stride=1时平均取值的卷积的效果,最右边为当stride=2时的效果,可以看到对原图进行了平滑处理,当stride=2的时候图像缩小,这里没有进行padding所以stride=1时图像也会变小。另外也可以取不同的卷积核进行不同的操作,能够得到不同的效果,卷积神经网络要学习的关键的部分就是这个。卷积神经网络中学习到的卷积核其实都对应这一定的特征。为什么卷积核能够对应一定的特征呢,我们可以以如下两个卷积核再次进行实验就可以看出卷积核中所隐藏的信息。
weights = np.array([[1,0,0],
[0,1,0],
[0,0,1]]).astype('float32')
weights = np.array([[0,0,1],
[0,1,0],
[1,0,0]]).astype('float32')
这里使用的是两个对角矩阵,只不过对角的方向是相反的,用他们对图片处理得到的效果如下,可以看到两个不同方向的卷积核分别将原图中对应的方向上的元素进行的加亮,而反方向的像素进行了平滑,其中中间为原图像,左右两边分别为处理得到的结果。

用im2col加速对图像的卷积运算
像我们上面的代码虽然能够对图像进行卷积操作,但是每次都需要把卷积核映射的区域抠出来,然后reshape为单维向量然后利用点乘,这样在大量图像或者大尺寸图像上进行计算效率非常差,可以用im2col的方式将image中要计算的区域一起抠出来作为一个column然后组成一个矩阵,最后一起进行计算,具体可以参看知乎问题在 Caffe 中如何计算卷积?

def im2col(image, ksize, stride):
m,n = image.shape
image_col = []
for i in range(0, m-(ksize-1), stride):
for j in range(0, n-(ksize-1), stride):
col = image[i:i+ksize, j:j+ksize].reshape([-1])
image_col.append(col)
image_col = np.array(image_col)
return image_col
卷积前向传播
前面对于卷积的计算以及使用im2col的方式加速计算完成了之后,对于卷积层的前向传播其实基本上就搞定了,剩下的无非就是考虑一下输入的batchsize和输入输出的通道(channels),还有需要增加的一个bias。首先将卷积层的权重weights矩阵reshape成[-1, self.output_channels]的形式,便于之后进行点乘计算,然后对于batchsize中的每一帧图像,用im2col提取要计算的column,然后就可以进行计算了。最后将每一帧的输出组合成batchsize大小的一个数组输出就行。
self.col_image_i = im2col(img_i, self.ksize, self.stride) conv_out[i] = np.reshape(np.dot(self.col_image_i, col_weights) + self.bias, self.eta[0].shape)
卷积神经网络
神经网络算法在很早就被提出了,但是最近几年才一直很热门,相关的一些算法包括DNN、CNN和RNN等在图像和NLP领域都广泛应用。卷积神经网络中最重要的操作是卷积和池化以及最后的全连接层,一些常用的开源深度学习框架都对cnn提供了很好的支持。这里看一下tensorflow中卷积神经网络的构成。
首先是对输入数据的处理,首先我们使用的tf.keras.datasets的MNIST的数据,每一帧为28*28的图像,label为数据1-9,所以需要将label数据变为onehot的表示,也就是0-1向量表示。然后就开始构建计算图。首先是输入的数据进行占位placeholder,这里输入为x和对应的y
x = tf.placeholder("float", [None,28,28])
y_ = tf.placeholder("float", [None, 10])
卷积层和池化层
CNN中最核心的就是卷积层了,卷积层需要训练的参数就是卷积核的权值,可以使用截断正态分布来初始化卷积核,如下,函数truncated_normal可以设置参数mean表示均值,stddev表示标准差。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
而卷积层和池化层可以直接调用tf的API进行表示,池化层可以减小计算量,并提取关键信息,包括最大池化、均值池化等,这里采用max pooling。从步长strides可以看出卷积层和池化层的对于图像大小的处理,这里池化之后图像将变为原来的1/4大小。
def conv2d(x, W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
这里对于mnist的数据使用卷积-池化-卷积-池化层这样比较简单的结构,首先第一层卷积层权重shape为[5,5,1,8],表示5x5的卷积核,对应的数表示[filter_height, filter_width, in_channels, out_channels],所以这里表示输入的通道为1,输出的通道为8,也就是有8个不同的5x5的kernel,对应学习不同的特征。值得注意的是这里的卷积层的输出用relu作为激活函数,结果输出到池化层。
关于 relu
relu是一种比较常用你的激活函数,貌似最先是在AlexNet中被提出来的,relu函数表示比较简单,为\(f(x)=max(0,x)\),其实就是把负激活给去掉了,可以增加神经网络的非线性特征,解决因为梯度消失而导致学习收敛慢的问题。
全连接层
第二层池化之后输出得到的是7*7的图像大小,为什么是7x7呢,因为图像开始是28x28,而每一层池化之后长宽都减半,所以两层之后图像就为7x7了,而通道是16通道,所以第二层池化后的结果一共为7x7x16,全连接层首先将这些结果进行拉直,也就是向量化。全连接层的参数也由第二层池化后的结果的shape决定,这里输出的维度设置为128,之后这128个结果再进行softmax得到最终的结果,这里的激活函数同样使用的是relu。
W_fc1 = weight_variable([7*7*16, 128]) b_fc1 = bias_variable([128]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*16]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
这时输出的维度有128维,并且输出的数量为batchsize个,这里有一个权重为[128,10]的权重矩阵,将128维的输出映射到最终的10个结果。
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([128, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
这里利用dropout来优化网络,关于dropout,通过如下图可以看到,其实就是对于有些来自上一层的结果,在输出到下一层的时候选择性丢弃,这里选择的概率为0.5,每个神经元被关闭的概率相同,dropout有助于防止深层神经网络中的过拟合。

训练及测试
使用交叉熵作为损失函数,目标就是minimize交叉熵,预测比照的时候直接对比计算得到的y_conv和输入的y_就行
cross_entropy = -1 * tf.reduce_sum(y_*tf.log(y_conv)) train_step = tf.train.GradientDescentOptimizer(1e-4).minimize(cross_entropy) correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
因为开源深度学习框架的存在,cnn的使用还是比较简便的,如果想深入了解cnn的具体计算过程,包括反向传播等细节,强烈推荐大佬 [@Wziheng](https://www.zhihu.com/people/wziheng/activities) 的专栏 [手把手带你 Numpy实现CNN](https://zhuanlan.zhihu.com/c_162633442)。
另外对于卷积神经网络的工作原理,知乎上有很多直观的描述:
https://www.zhihu.com/question/39022858
另外还有一个卷积神经网络的3D视觉化模型,由作者Adam Harley创建,可以直观的看到卷积神经网络的内部工作过程:
http://scs.ryerson.ca/~aharley/vis/conv/
VGG网络
VGG是是一个使用非常广泛卷积神经网络模型,在论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》被提出,最开始是用Caffe做的,所以若要利用tensorflow来做的话,可以参考:
其实主要就是把Caffe中训练出来的模型的weights利用特殊工具转成tensorflow能够使用的模型,这样就省去了大量的训练时间,模型转换可以参考: https://github.com/ethereon/caffe-tensorflow 。
这里使用上面链接中作者提供的一张图片来介绍VGG16的架构,实验代码也均可以从中进行下载,运行程序需要安装scipy的包,可以替换测试图片为任意其它图片,也能够识别。
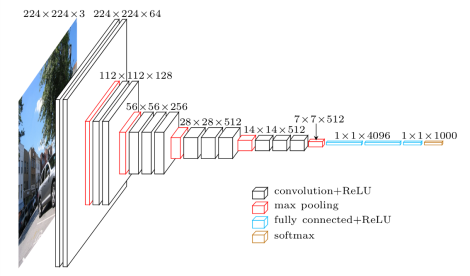
已经训练好的model以npz格式进行存储,这里大概500MB,numpy库可以直接进行读取,可以用scipy.misc的库读取图片并图片进行处理,如改变读入图片数据的size,首先按如下操作读取npz文件,并重建vgg模型,在vgg16的类中会进行卷积层和全连接层的出事话工作,并会加载读入的权重矩阵。关于npz格式和npy格式,默认情况下numpy存储数组是保存为npy格式,可以用np.load和np.save进行操作,而npz格式可以将多个数组保存到一个文件中,这时就可以使用np.savez进行操作,同样利用load进行读取,只不过读取之后对应不同的item名会有不同的数组。
sess = tf.Session() imgs = tf.placeholder(tf.float32, [None, 224, 224, 3]) vgg = vgg16(imgs, 'vgg16_weights.npz', sess)
VGG16 卷积层
卷积层代码主要结构如下,最开始有一个预处理preprocess层,是将输入的images中的rgb三值减去ImageNet中训练集的平均值。在self.parameters添加参数,之后可以通过读取之前训练好的weights数据,直接用numpy的接口读取成key,value的数据并对各个参数初始化,就没必要训练了。当然参数的设定过程在tensorflow中需要一个op来完成,因为只有Session在run之后assign参数才有效。
def convlayers(self):
self.parameters = []
# zero-mean input
with tf.name_scope('preprocess') as scope:
mean = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32, shape=[1, 1, 1, 3], name='img_mean')
images = self.imgs-mean
然后便是各种卷积层和池化层,各个卷积层之间的区别主要在于kernel的参数,也就是kernel的大小不同,而各个pool层在这里参数都设置为相同了。
# conv1_1
with tf.name_scope('conv1_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 3, 64], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv1_1 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
# conv1_2 #kernel = [3, 3, 64, 64]
# pool1
self.pool1 = tf.nn.max_pool(self.conv1_2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool1')
# conv2_1 kernel = [3, 3, 64, 128] + conv2_2 kernel = [3, 3, 128, 128]
# pool2 ksize=[1, 2, 2, 1] strides=[1, 2, 2, 1]
# conv3_1 kernel = [3, 3, 128, 256] + conv3_2 kernel = [3, 3, 256, 256] + conv3_3 kernel = [3, 3, 256, 256]
# pool3 ksize=[1, 2, 2, 1] strides=[1, 2, 2, 1]
# conv4_1 kernel = [3, 3, 256, 512] + conv4_2 kernel = [3, 3, 512, 512] + conv4_3 kernel = [3, 3, 512, 512]
# pool4 ksize=[1, 2, 2, 1] strides=[1, 2, 2, 1]
# conv5_1 kernel = [3, 3, 512, 512] + conv5_2 kernel = [3, 3, 512, 512] + conv5_3 kernel = [3, 3, 512, 512]
# pool5 ksize=[1, 2, 2, 1] strides=[1, 2, 2, 1]
VGG16 全连接层
全连接层一共三层,接收上面卷积层后第5层池化得到的结果,输入全连接层第一层。这三层全连接层都是用一个权重矩阵来表示转换的过程,最后的结果为1000维,分别描述了1000个场景,也就是1000个语义,这里在imagenet_classes中以及描述了。
def fc_layers(self):
# fc1
with tf.name_scope('fc1') as scope:
shape = int(np.prod(self.pool5.get_shape()[1:]))
fc1w = tf.Variable(tf.truncated_normal([shape, 4096],
dtype=tf.float32,
stddev=1e-1), name='weights')
fc1b = tf.Variable(tf.constant(1.0, shape=[4096], dtype=tf.float32),
trainable=True, name='biases')
pool5_flat = tf.reshape(self.pool5, [-1, shape])
fc1l = tf.nn.bias_add(tf.matmul(pool5_flat, fc1w), fc1b)
self.fc1 = tf.nn.relu(fc1l)
self.parameters += [fc1w, fc1b]
# fc2 [4096] * [4096,4096] + [4096]
# fc3 [4096] * [4096,1000] + [1000]
FCN与语义分割
2015年的一篇论文《Fully Convolutional Networks for Semantic Segmentation》提出的FCN也就是全卷积神经网络,可以使得图像语义分割的正确率大大提高,
github上现在找到了两个实现,都是基于该论文实现,首先是:https://github.com/shekkizh/FCN.tensorflow.git ,这个实现包含了训练过程,其针对的数据是MIT场景识别的数据,代码作者在12GB的TitanX GPU上训练花了大约6~7个小时,所以硬件要求较高,暂时保留。
另一个实现是: https://github.com/MarvinTeichmann/tensorflow-fcn ,这个实现不需要再训练模型,直接使用vgg已经训练好的权重矩阵,就像上面介绍的VGG16中使用的npz文件一样,所以就省去了很多时间,而且很容易把这个实现集成到我们自己的语义分割实现中。不仅仅提供了对应于VGG16的FCN16,还有FCN8和FCN32。运行需要准备的库包括:numpy,scipy,pillow,matplotlib, 另外模型文件下载: ftp://mi.eng.cam.ac.uk/pub/mttt2/models/vgg16.npy
语义分割
语义分割主要是需要对像素点进行分类,传统的基于CNN进行语义分割的方法对于每一个像素需要提供这个像素周围的一个像素块作为CNN的输入,分类的结果作为该像素的分类。这样做的话首先是每一个像素都要很大的存储空间,并且在计算上存在大量重复的计算,并且这个感知区域只能提取局部的特征,像素分类的性能受限。

FCN对此进行了改进,VGG网络中,经过多次卷积池化之后,图像大小变为原来的1/2、1/4、1/8、1/16、1/32,FCN对缩小后的图像进行上采样来获取和原图一样的大小,这个上采样的过程采用的是反卷积的方法,在第五层卷积池化之后反卷积获得的图像不够精确,所以作者对第四层和第三层结果也进行了反卷积。
反卷积

这里使用反卷积的目的是从最后池化后较小的图片得到与原图相同大小的图像,反卷积的计算过程其实与卷积相同,只不过从尺寸小的图片得到原图像时需要先在中间部分地方补充0,然后再利用之前卷积池化中的卷积核进行卷积。
如下为对一个2x2的图像使用4x4的卷积核进行反卷积得到7x7图像的操作,其中采用的滑动步长为3,首先对输入图像的每个像素进行一次full卷积,根据full卷积计算方式,而卷积核大小为4x4,所以每个像素卷积后大小为1+4-1=4,共4个像素得到4个4x4的特征图,然后根据步长为3,也就是每隔3个像素进行一次fusion,也就是重叠的部分进行相加,最后得到7x7的图像。

总结下,如果insize为输入大小,ksize为卷积核大小,stride为步长,outsize为输出大小,那么有:outsize=(insize-1)*stride + ksize
回到FCN中的反卷积上采样操作,作者实现了有对第五层、第四层及第三层池化层进行反卷积得到原图的方式,分别对应的stride为32、16和8。
全卷积网络及tensorflow实现
首先先明确一下FCN中的全卷积指的是将最后的全连接层也替换成卷积层,并且分别从第五、四、三层卷积池化结果做反卷积得到结果与最终的全卷积层做一个fusion,也就是加和来得到最终结果。这里代码引用自:https://github.com/MarvinTeichmann/tensorflow-fcn ,这里使用的是fcn16的代码。

首先看一下最后的全卷积层,包括两层
self.fc6 = self._fc_layer(self.pool5, "fc6") self.fc7 = self._fc_layer(self.fc6, "fc7")
然后是两个上采样层以及全卷积层的结果和pool4的结果的一个fusion,也就是聚合操作。需要注意的是这一步只是将全卷积层反卷积到与pool4相同的大小,这样两者就可以进行加和,后面还有最后根据pool4大小的图像进行反卷积得到最终结果的操作。
self.upscore2 = self._upscore_layer(self.score_fr,
shape=tf.shape(self.pool4),
num_classes=num_classes,
debug=debug, name='upscore2',
ksize=4, stride=2)
self.score_pool4 = self._score_layer(self.pool4, "score_pool4",
num_classes=num_classes)
self.fuse_pool4 = tf.add(self.upscore2, self.score_pool4)
在上采样的函数_upscore_layer中调用了tensorflow的反卷积的操作tf.nn.conv2d_transpose
def _upscore_layer(self, bottom, shape,
num_classes, name, debug,
ksize=4, stride=2):
strides = [1, stride, stride, 1]
...
weights = self.get_deconv_filter(f_shape)
deconv = tf.nn.conv2d_transpose(bottom, weights, output_shape,
strides=strides, padding='SAME')
...
最后对fuse_pool4再次反卷积得到最终的结果,并根据结果中的类别预测值的大小用argmax选择像素对应的类别值。
self.upscore32 = self._upscore_layer(self.fuse_pool4,
shape=tf.shape(bgr),
num_classes=num_classes,
debug=debug, name='upscore32',
ksize=32, stride=16)
self.pred_up = tf.argmax(self.upscore32, dimension=3)
RCNN与目标检测
RCNN为论文《Regions with Convolutional Neural Network Feature》中提出来的基于CNN用于目标检测的一种方法,CNN的特点就是对整张图片进行卷积池化等操作,利用分类标签进行BP训练然后生成Feature Map,而目标检测的目的是寻找图像中的某块区域进行标注,所以将CNN引入目标检测的话基本思路就是将图像分割成不同大小的矩形区域,这时候主要需要学习的就是这个矩形框的大小以及位置,所以需要进行生成候选区域、特征提取、分类以及位置精修等操作。
RCNN
RCNN进行目标检测的网络结构如图,比如首先对输入的图像选择2000个候选框,然后用CNN提取每个候选框的特征向量,各个候选框的特征向量维度相同,比如4096维,最后根据这些特征对候选框进行分类,可以采用SVM等分类方法。

首先利用selective search进行图像分割,selective search进行图像分割的方法主要是首先将图像分割为多个不同的区域region,然后利用聚合的方式将小的region聚合成大的region,主要是计算region之间的相似度,合并相似度最大的两个region,重复此过程最后得到一定数量的候选框
CNN网络结构可以选取AlexNet或VGG16等,VGG的准确率更高但是计算量也更大。CNN训练的输入为前面选取的多个候选框图,因为训练数据不足的原因,可以用其它任务以及训练好的模型或者其他任务的数据训练模型来初始化模型作为预训练,也可以进行fine tuning,若物体类别为N,可以将最后一层大小设为N+1,将背景也当做一种类别。
最后使用SVM对每个类别进行二分类得到候选框的类别,可以引入脊回归L2范数进行优化。这里为什么要再使用SVM进行分类呢,为什么不用CNN直接softmax进行分类呢,主要是CNN训练分类的时候容易出现过拟合,所以需要大量的训练数据,而为了得到大量的训练数据就会放宽标注的数据要求,比如只包含某个物体的一部分也会被标注为正样本,而SVM就不同,可以用于少样本训练,对于训练样本的数据要求比较严格,只有当完整包含该物体时才会被标注为正样本。
RCNN主要问题在于生成的候选框数目过多,导致训练和测试过程非常慢,并且精修过程需要额外训练。
Fast RCNN
相对于RCNN,fast RCNN主要改进的点是输入的时候将整张图作为输入,不需要提前划分候选区域,并且将精修过程加入到网络中。首先将图像缩放到224x224大小输入到网络,之后接多个卷积层,然后利用ROI Pooling提取出特征,然后特征层分别连接回归Loss和分类Loss。相对于RCNN,fast解决的是为什么不一起输出bounding box和对应的标签呢,因为分开的话用selective search产生对应的标签的时间太长了。
关于ROI Pooling,ROI Pooling的思想来自于Spatial Pyramid Pooling空间金字塔池化,SPP的目的主要是解决CNN中不同尺寸大小图像输入的问题,CNN中全连接的输入的尺寸是固定大小的,所以这时候就会对输入数据进行剪切等操作,可能导致失真,而加入了SPP层之后网络输入可以任意尺度,而输出尺度却固定。

应用到RCNN中,RCNN中是先选择多个候选框,然后resize到同一大小作为CNN的输入,而SPP的话可以用原图进行CNN的输入,然后找到候选框在整个feature map上的patch,这个patch作为候选框的卷积特征作为后面层的输入,这样相当于把候选框的选择和候选框的feature map的生成一同完成了。ROI Pooling可以看做是单层的SPP网络,可以把大小不同的输入映射到一个固定尺度的特征向量,卷积池化以及relu等操作不需要固定size的输入,所以在这些操作完成后再连一个ROI Pooling就可以将不同大小图片的输入最终产生相同大小的输入特征用于分类。

比如ROI Pooling可以在Feature Map中将候选框分成一个一个3x3的区域,然后分别Pooling出3x3的Feature Map,然后输入到下一层,这样就可以保证往下的输入的特征尺度相同。
Faster RCNN
相较于RCNN,fast同样使用了selective Search,由于这个选取候选框的工作非常耗时,所以Faster的主要工作就是寻找一个更加高效的选取候选框的方法,于是RPN网络就出现了,Region Proposal Network。将整整图片经过卷积层之后得到的feature map输入到rpn层获得候选框的信息,然后用分类器判断,并用回归器调整候选框的位置。

关于RPN,功能是将候选框的选取、分类和修正都集成到一个框架,在feature map上滑动窗口,建立一个神经网络用于物体的分类和候选框位置的回归。这里用到Anchor的方法,选取3中类型对应三种大小,也就是总共九种Anchor来减小计算量,每一个anchor后面接一个二分类softmax函数,后面接用于分类和回归的两个score。

关于Faster RCNN的训练过程,首先需要单独训练RPN网络,然后用生成的候选区域来训练Faster RCNN的分类和修正的网络,然后再次训练时固定公共的部分,只更新RPN部分和微调Faster RCNN部分。
注:本文只是个人总结,欢迎讨论,部分图片来源于网络,侵删。